Before a production-ready data science model is built, there’re usually dozens of iterations within the data science team and across outside teams. In this context, internal iteration refers to the technical iterations that only data scientists are involved in. Cross-team iteration happens at a point that data scientists have a well-performed model, and need the review of business, compliance and/or product units. While cross-team iteration is essential to the success of a product, the importance of this step is often underestimated.
Internal Iterations
Most data scientists are very familiar with internal iterations, since the model building process is pretty standard. Essentially we evaluate model performance by various metrics like accuracy, precision, recall, AUC, and f1 score etc. Depending on the use case, sometimes one metric is more important than the others.
For example, if we were to build a terrorist detection model, we’d care more about recall than precision. This is because a false positive is more tolerable than false negative, meaning that falsely identifying good people as terrorists is better than falsely identifying terrorists as good people. Data scientists pick the right metric to use based on the business case and find the best model.
However, from our experience working with Pivotal, the process is a bit different than what people usually do for first, the nature of developing work differs from researching work. Second, Pivotal’s product, Greenplum, provides technology advantages that people normally don’t have access to.
In our process, we generate a huge set of features beforehand, and work through many iterations in a short period of time. This includes model selection, grid search, cross validation, and feature correlation analysis. Once a clean, well-performed model is built, we move on to cross-team iteration. That is, having the business/product stakeholders to validate the model and get feedback.
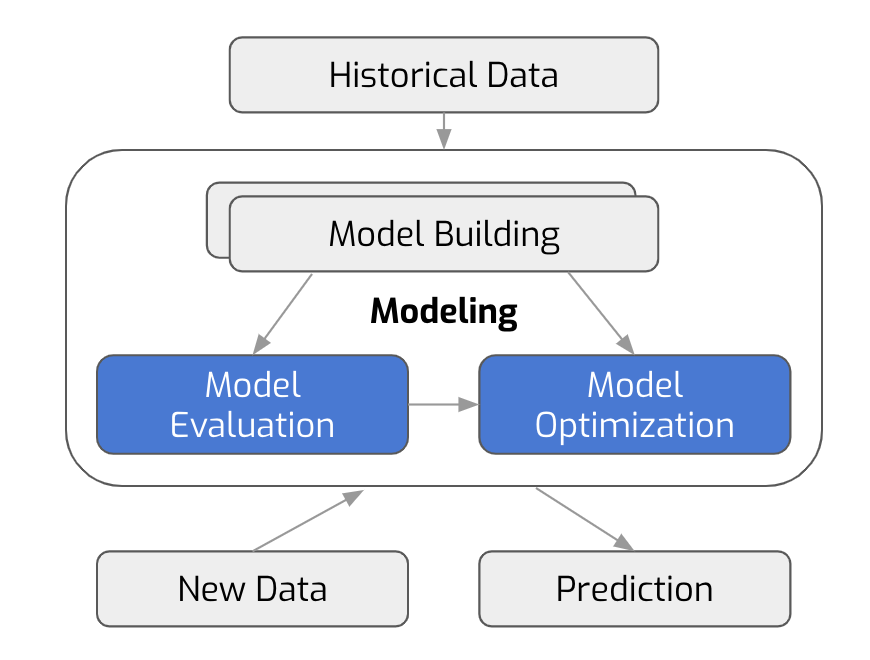
Model Evaluation/Improvement Process
Cross-team Iterations
Cross-team iterations refer to the process of having a model reviewed by other team(s) with interest, like the product team. Let’s say we’ve already built a campaign model that targets account holders who’d likely to respond to an offer.
In a cross-team evaluation session, we bring the model to the product team, who have been in charge of running the campaign for years. By demonstrating the model performance, along with important features, the team could provide some insights or blindspots that weren’t clear to the data scientists.
This is a great opportunity for data scientists to identify pitfalls and/or potential leakage (data that shouldn’t be included in modeling) , which would cause problems were they not captured in the development phase.
To conduct successful cross-team evaluation, it’s important to know your audience. Data scientists should be aware of the characteristics of the group of people who they’ll be presenting to. For example:
- What’s their technical skill level?
- How much detail should you provide to keep it both informative but not confusing?
- What are they expecting from your model?
- What do you want to get out of the meeting?
These are all the questions that data scientists should have answers to before they walk into an iteration meeting. This is even more important when your audience does not yet have faith in data science, since it’s fairly new to most people.
In our last engagement, we went through two iterations with a product team, who were mainly non-technical, though they had strong domain knowledge. The goal of the information exchange was clear: we provided our methodologies, model results, and feature importances for them to review. Meanwhile, we asked for model results validation, and whether the features we used make sense to them. After two iterations, both teams agreed that the model was production-ready.
In short, we want an effective and efficient two-way communication process, rather than just presenting our work or asking questions. Cross-team collaboration is no less important than any other step in the process.
What To Do When Conflict Happens
Sometimes conflicts happen between the product team and data scientists. For example, one of your important features may not make sense to them. They may disagree with how you processed the features, or be dissatisfied with the output of the model.
When this happens, we tend to defend our approach, especially when we’re more knowledgeable and confident in our model. Oftentimes, there’s no problem with the approach itself. However, a perfect model doesn’t deliver value - the ultimate product does. Data scientists should take this feedback in a positive way and find a way to achieve a win-win situation.
If a light hit on model performance increases stakeholders’ faith in the product, it’s definitely worth the compromise. On the other hand, if what they’re asking for affects the model/data integrity - such as biasing the model - that’s something we should fight for. Be ready to make compromises that make everybody happy, and only pick the fights that are necessary. A valuable product is the goal, rather than a hypothetical perfect model.
In my next post, I’ll talk a little bit about operationalization (yes it’s a word!), which is usually the last engineering piece of a data science product and has a direct impact on product sustainability.
