As more and more companies have embraced the power of data science, integrating it into their production process becomes an inevitable challenge. Data science is a unique discipline, in that it exists between software development and research. Because of this, understanding the pros and cons of existing methodologies is crucial to the success of a product.
Nowadays, most companies treat a data science project as a two-step process: research, then engineering. That is, data scientists do the research and finalize the model, then hand over to software engineer/IT for ETL and model deployment. This is inefficient in many ways. For one, communication between teams can be time-intensive. In addition, engineers can take time to ramp up on the intricacies of a model built by another.
The preferable approach, when possible, is to integrate both steps of the two-step process into software development, increasing efficiency and improving the rate of success. In this post, I’ll first introduce an industry-standard data mining process, CRISP-DM, and follow with a derived approach, Pivotal’s agile data science process.
What is CRISP-DM?
CRISP-DM stands for Cross-Industry Standard Process for Data Mining. It’s a conventional process that is used by data mining experts. The process has the following six phases:
- Business Understanding: Learn the domain, clarify the goal, and make a plan.
- Data Understanding: Know the data in all aspects (format, source, structure etc.)
- Data Preparation: Preprocessing and feature engineering.
- Modeling: Build the model.
- Evaluation: Evaluate model performance.
- Deployment: Deploy the model to end users.
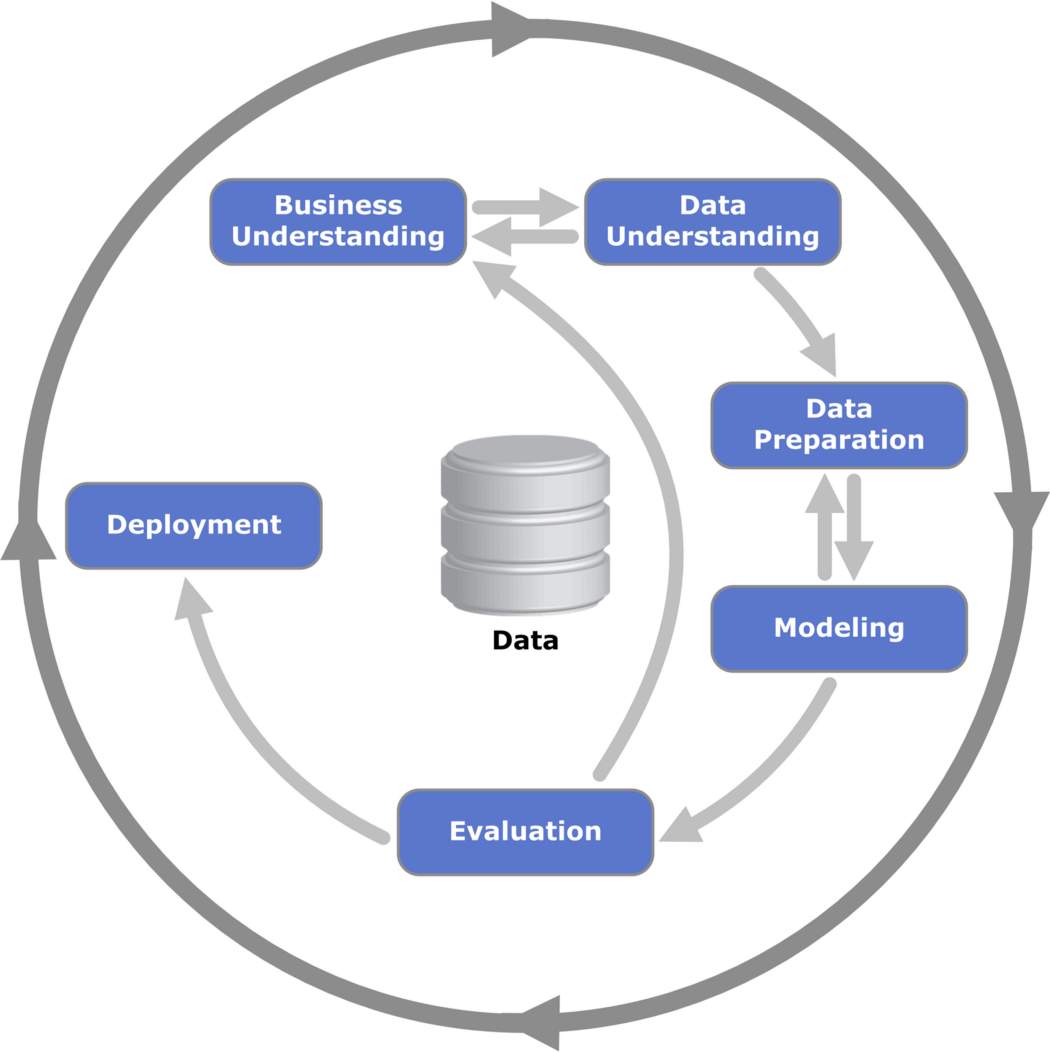
Cross-Industry Standard Process for Data Mining (CRISP-DM) By Kenneth Jensen
The cycle process provides a nice overall guideline for an end-to-end data science product. However, things become more complicated when tied to a product cycle, especially in the case of a modeling product.
In reality, the business climate often changes, and what features drive the business decision today might change in months, weeks, or even days. A periodic update (re-fit) of the model product is needed for most business cases.
In this situation, CRISP-DM seems to have failed to provide a comprehensive strategy to handle what comes after deployment. This is when agile data science comes into play.
Working with Pivotal: An agile approach
In our experience partnering with Pivotal Data Science Team, we learned an agile approach to data science and how the process is suited for product-oriented projects. Let’s take a recap of agile development concept.
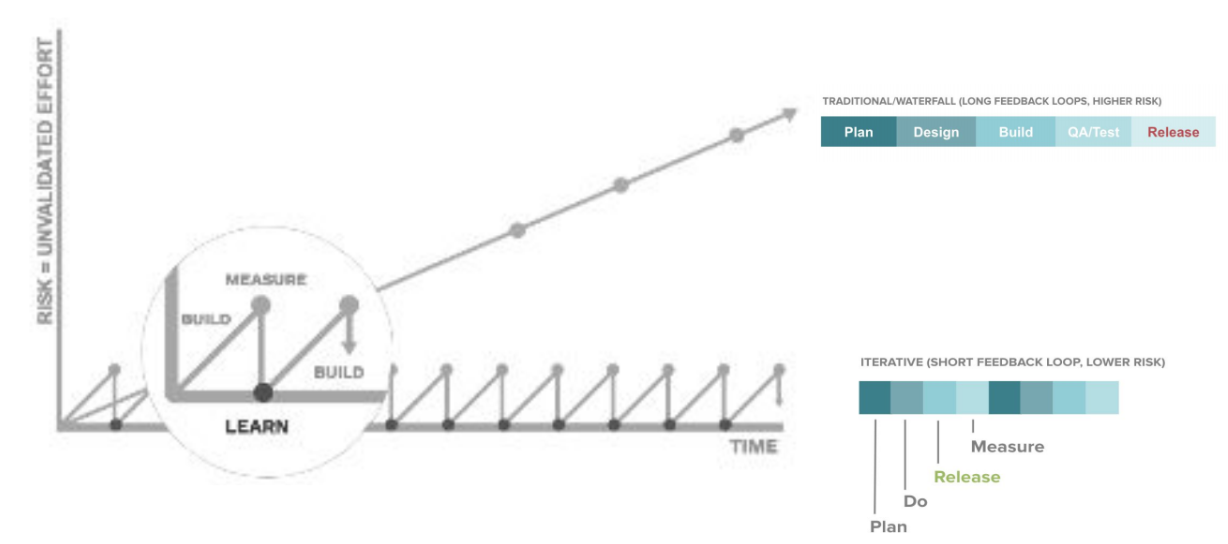
In an agile development process, the development cycle is shrunk to minimal. Instead of spending a lot of time in each phase that exhausts our entire timeline, we shrink down the effort to short cycles and improve our work by running through many iterations.
The benefit of this approach is shown in the diagram below. The risk of development reduces significantly as we can constantly adjust our course to make sure it’s aligned with business.
So what does an agile data science process look like? Let’s take a look at the diagram below. The key to agile data science is that we start from building a minimal viable model as the baseline, then refine the model by running through multiple iterations.
How many iterations are there? As many as the timeline allows. In a product-oriented environment, timeline is always a concern, which makes this approach advantageous. In this process, we might or might not build the ‘perfect’ model, but we can certainly deliver a model that has business value.
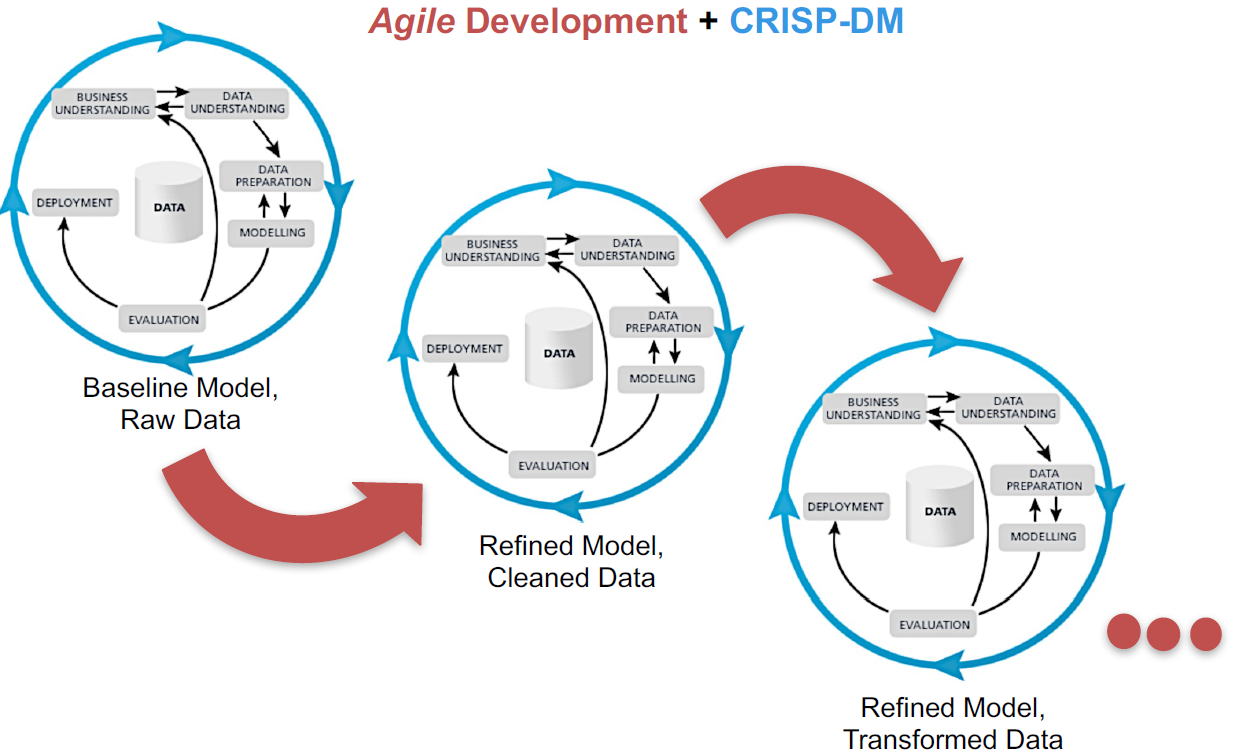
Agile Data Science Diagram by Elderresearch
In our experience working with Pivotal, we found this approach very practical for companies who are looking to start doing data science. By practicing the process with us, our client's data science team not only learned the concept, but the techniques of practicing it. With the modules and frameworks we built during the engagement, our clients were able to run through the entire end-to-end pipeline and continue to deliver value.
Now we see the benefits of the agile data science process, what about the bad? How exactly does it work in practice? It’s definitely not a one-for-all solution. There’s pros and cons in this approach as any other approaches, and there’s a lot of nuances in the process that we need to be aware of. In future posts, I will discuss many of the major details in Pivotal’s agile data science process. To learn more, read my next post about the role pair programming plays in the agile data science process.
