GAN Basics
Introduced in 2014 by Ian Goodfellow, Generative Adversarial Networks (GANs) have taken a center stage of recent Deep Learning discoveries. In fact, Yann LeCun, who pioneered CNNs, describes GANs as “the most interesting idea in the last 10 years in Machine Learning”.
We will cover:
- Overview and definition of a GAN
- GAN Training
- Use Cases
- Limitations
- Alternatives
GANs are a generative model. They use unsupervised learning to learn the underlying structure of given data to generate their own synthetic data of the same type.
A GAN consists of 2 models, a Generator and a Discriminator, both of which are generally modeled using Neural Networks. It’s suffice to say the essence of a GAN is the adversarial relationship between these 2 networks.
The Generator and Discriminator are analogous to an art forger and a detective, respectively. The art forger is tasked with creating artwork that could pass as the original. While the detective’s purpose is to find the fraudulent artworks by discovering discrepancies between the original and fake.

GAN Training
Let’s walk through the training process for a basic GAN.
GAN training consists of training the underlying generator and discriminator neural networks. In general, we know that neural networks are trained by finding the optimal weights that map the input neurons to the desired output through a process called backpropagation.
Discriminator Training
Our generic definition certainly holds true for the discriminator.
- The discriminator attempts to classify both real data and fake data from the generator.
- With the goal of minimizing misclassifications, the model will update a loss function when the model is incorrect.
- The discriminator will iteratively learn by updating its weights through backpropagation to minimize the loss.
Generator Training
Training the generator is a little more involved conceptually. as we have to calculate its loss indirectly — through the discriminator network. In other words, backpropagation must start at the discriminator and work its way back through to the generator.
- The generator initially outputs obvious fake data.
- The discriminator classifies the generator output as fake.
- We calculate loss and backpropagate through the discriminator and the generator.
- Change generator weights to maximize the loss function.

Significant Research and Advancements
Goodfellow’s GAN has paved the way for remarkable progress for Deep Learning applications in computer vision, specifically in text-to-image translation, image-to-image translation, and image generation.
We consider the following 4 papers as “must reads” to understand the current landscape of GANs.
DCGAN
This paper proposes a set of architectural guidelines to successfully train a GAN using convolutional neural networks rather than traditional neural networks, thus the name, Deep Convolutional GAN (DCGAN).
The GAN is built as follows:
- Generator uses fractional-strided convolution layers, batchnorm, and ReLU activation for all layers except output which uses Tanh.
- Discriminator uses strided convolution layers, batchnorm, and LeakyReLu activation for all layers.
The authors prove the effectiveness of the approach by running a series of image classification tasks, showing competitive performance with other unsupervised algorithms.
Additionally, the paper shines light on some of the internal workings of the generator and discriminator. They explore the latent space, visualize the inner layers/features of the discriminator, and manipulate generator features to control its output.
cGANs
cGANs provide a really interesting adaptation of the vanilla GAN. This architecture provides additional input to the generator and discriminator, generally a one-hot encoded vector, to specify the class/label of the generated output.
The paper provides MNIST as a PoC, encoding each of 10 digits and generating each one deliberately with great accuracy.
The following illustrates the structure of the cGAN. As you can see, a vector y is fed into both the discriminator and generator as an additional input layer.
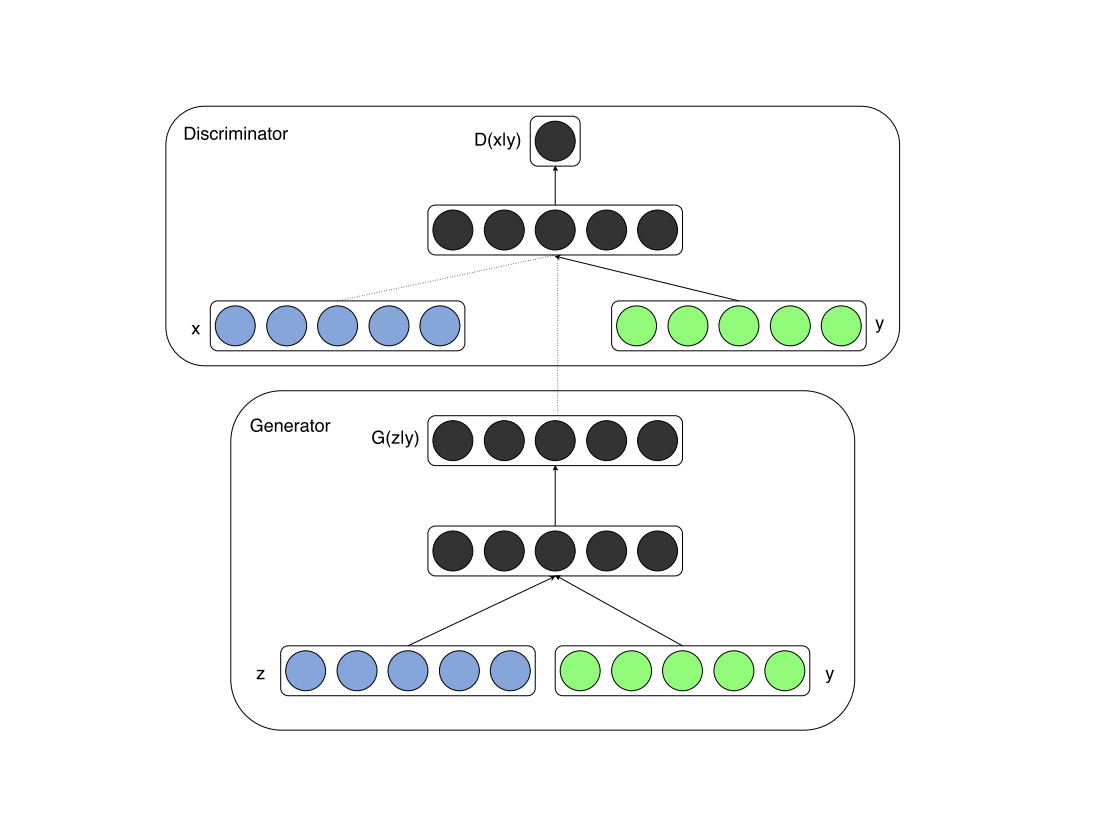
StyleGAN & StyleGAN2
NVIDIA’s Style Generative Adversarial Network (StyleGAN) introduced extensive changes to the generator model in order to generate hyperrealistic, high-quality photos of faces while also allowing for control over the quality and style of the output.
StyleGAN uses the progressive growing GAN technique (PGGAN), which upscales the discriminator and generator models incrementally during the training process.
While research techniques at the time had explored the discriminator model, the generator “continue[d] to operate as [a] black box.” The author’s explain that they hoped to better understand the image synthesis process and the corresponding latent space that took place in the generative process. They coupled PGGAN’s iterative introduction of layers with corresponding features. Thus, the lower the layer (and the image quality), the courser the features. This concept, along with several additions made StyleGAN one of the best performing GANs.

Images generated by StyleGAN from GitHub
StyleGAN2 was developed subsequently to fix common issues with its predecessor.
Namely, StyleGAN2 removed water droplet type objects that would appear in StyleGAN images. Secondly, StyleGAN2 improved the “phase” of generated images - solving an issue where parts of the image would be misaligned contextually. Lastly, StyleGAN2 was able to further improve image quality as well using new techniques to condition the latent space.
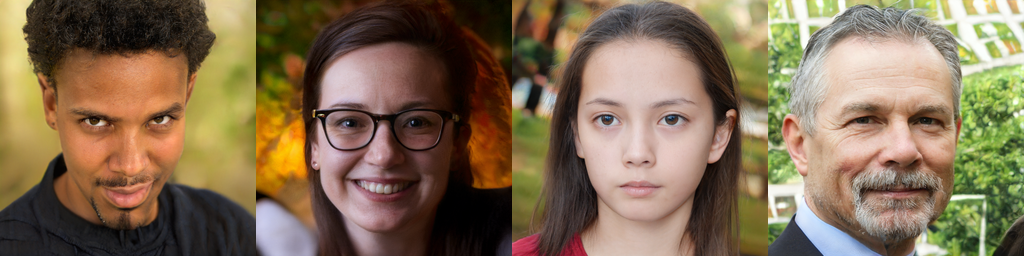
StyleGAN2 Images from GitHub
Generate StyleGAN images yourself - https://www.thispersondoesnotexist.com/
Pix2Pix
A majority of GAN models are built to generate synthetic data, converting noise to a discernable image or other output. Pix2Pix is an outlier. The Pix2Pix GAN is a model for doing image-to-image translation. Image-to-image translation can range from changing the time of day in photographs to translating a sketch into an actual image. To accomplish this, Pix2Pix builds on the cGAN as it takes an additional constraint - an image - to create the desired output image as seen below.
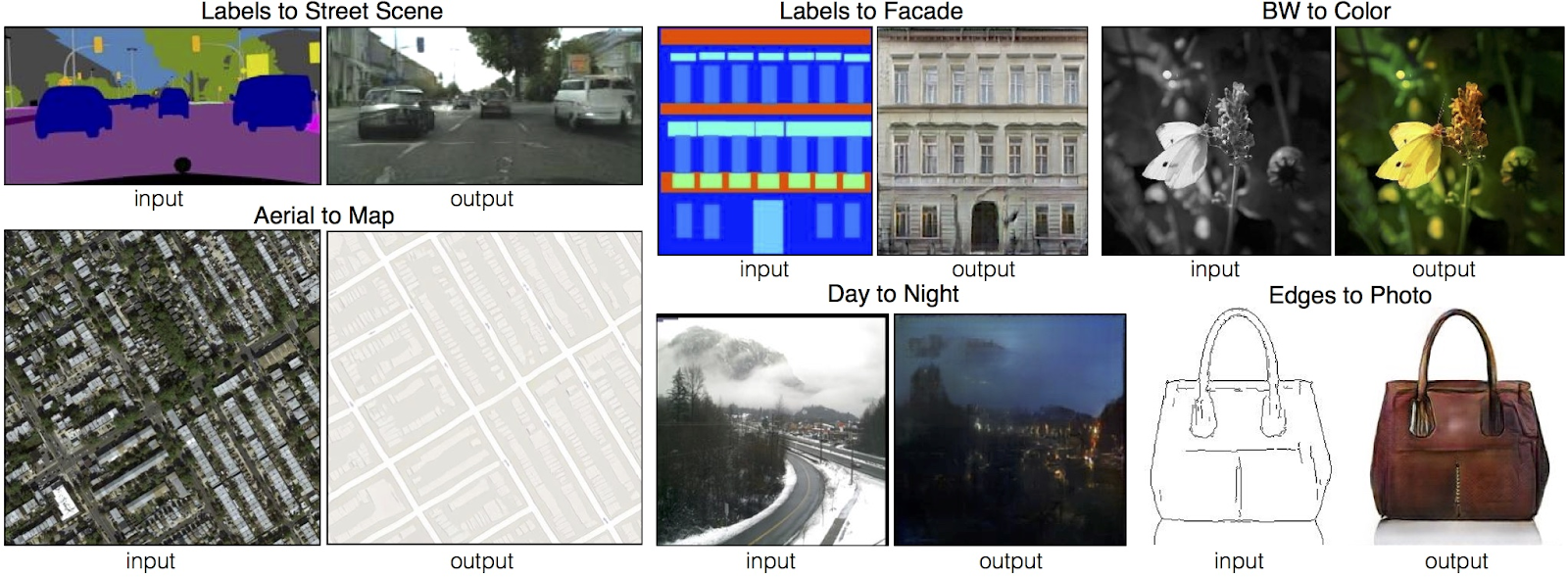
Image taken from Pix2Pix paper
Try it out yourself with the following interactive demo - https://affinelayer.com/pixsrv/
CycleGAN
CycleGAN also solves an image-to-image translation problem. The model allows for a new synthetic image to be generated with a specified modification to an input image. This problem could also be solved with a supervised deep learning model, however this would require a paired dataset for the model to understand the input/output. However, CycleGAN employs the unsupervised GAN model to generate modified images without a paired dataset.
CycleGAN simultaneously trains two generator models and two discriminator models. The process involves the first generator taking an image from the first domain as input and outputting an image in the second domain. The second generator then takes images from the second domain and outputs images to the first domain. This process is known as cycle consistency. Finally, the Discriminator models are used to scrutinize the generated images and update the generator models.

Image taken from CycleGAN paper
GAN Use Cases
Financial Services
- There is exploratory research behind using CGAN training to learn and simulate financial time series data. A popular time series forecasting tool currently involves Monte Carlo Simulation. This proposed CGAN model provides more robust data as the CGAN learns to depict a variety of auxiliary information.
- Researchers have proposed a GAN model to assign a probability that a given transaction is fraudulent. The model utilizes a deep denoising autoencoder in conjunction with the GAN to find patterns in fraudulent transactions. Implemented in 2 commercial banks, who have seen reduced losses of about 10 million RMB (bank funds) in twelve weeks and significant improvement in their business reputation.
Healthcare
- Researchers are using GANs to facilitate drug discovery and novel drug creation.
- Development of medGAN, which generates synthetic electronic health records (EHR) to allow for computational advancements in medical research while mitigating privacy concerns.
Marketing/Advertising
- Rosebud.ai provides various content creation applications. They provide user friendly apps that allow: portrait photo animation, customizable synthetic portrait images, and AI face filters. Market exposure to industries like modeling, digital marketing, and cosmetics.
- RunwayML is an extremely comprehensive content creation platform utilizing StyleGAN. Features include: video editing tools like synthetic green screens and cutting objects out of videos and user friendly platform allowing users to choose custom data sets and GAN techniques to generate synthetic images and videos.
- A team at Zalando Marketing Services recently released a research paper detailing how to generate high-resolution images of fashion models with customizable outfit and body stances from a predetermined set. Likely targeting the apparel and digital marketing market.
eCommerce
- Researchers at Stanford University explored how GAN models can generate property listing descriptions on AirBnB. They used a defined set of successful listings and developed a model to recommend a way to reword the phrasing of a listing to increase the chance it is booked.
- eCommerceGAN was invented to generate any number of potential orders. Researchers were looking to replicate the underlying structure of orders given the fact that customers and products can be grouped together. For example, customers are often grouped based on “similarity of purchase behaviors, price/brand sensitivity, ethnicity, etc.”, and products are often grouped based on “product categories, subcategories, price ranges, brands, manufacturers, etc”. The GAN learns this distribution and applies it to create plausible orders.
IoT
- The GANSlicing paper demonstrates a solution to the high resource demands of mobile networks as IoT and mobile devices grow more complex. Author proposes a dynamic and flexible mobile network slicing method that leverages predictions generated by GANs to dynamically and flexibly allocate resources like internet bandwidth.
GAN Limitations
There are a few common challenges associated with GAN training. These challenges are also described in more detail here.
Mode Collapse
It’s easy to think of Mode Collapse as if the generator is becoming “lazy”. When the generator creates one or a few very similar data points that happen to be the most plausible to the discriminator, the generator will learn to only produce those points.
This generally happens when the discriminator reaches a local minimum and is thus not able to distinguish between the fake and real data. Without feedback to adjust from the discriminator, the generator will keep generating similar output.
Potential Fixes
- The Wasserstein loss GAN is a popular GAN adaptation which lets you train the generator without letting the discriminator get stuck at local minima. It does so by rejecting the outputs when it detects a mode collapse, forcing the generator to keep training.
- The Unrolled GAN adaptation was developed specifically to combat mode collapse. It does so by training the generator on a more involved loss function that incorporates “not only the current discriminator’s classifications, but also the outputs of future discriminator versions”. This keeps the generator from collapsing on a single discriminator.
Failure to Converge
This is another prevalent problem for GANs. There is no guarantee that the gradient updates provided by the discriminator will result in convergence. Ideally, the GAN will reach a Nash equilibrium, the optimal point to the following equation.
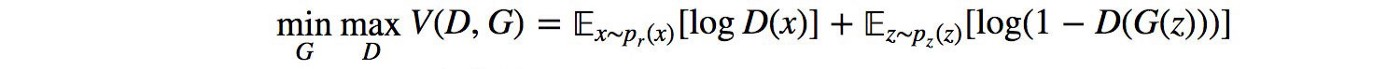
To identify convergence failure, one should observe the discriminator and generator loss. We can assume that if the model fails to converge, the generator will be producing bad examples and the discriminator will be distinguishingly them quickly. This would mean that our discriminator loss would be very low and our generator loss would be very high.
GAN Alternatives
Variational Autoencoders
The Variational Autoencoder model shares similarities to cGANs as they can both be used for conditional image generation using an adversarial approach. While the authors who developed the model did not reference GANs, they share many features. The encoder is a convolutional neural network trained to generate parts of an image given the surrounding context.
This article was written as part of a data science internship. We hope you found the content as valuable as we did.
If your organization is interested in implementing GANs and/or has questions about this article, please contact us at info@A42Labs.io.
