Enron is one of the most notorious examples of corporate malfeasance. In 2001, fraudulent accounting practices led to the biggest bankruptcy in history at the time, resulting in a loss of $6 billion in assets. The relatively primitive document compliance procedures of the time meant that a lot of bad actors fell through the cracks. And while compliance technologies have become more sophisticated, the sheer amount of information companies now have to monitor present an ongoing challenge.

Companies spend millions each year to ensure compliance among their employees’ communications. The terabytes of internal communications and attachments companies must analyze every year presents significant implementation problems. Electronic document compliance solutions currently available on the market use inferior classification techniques and can’t be easily customized for organizational data.
The result is an inefficient and ineffective approach to document compliance. One common approach is to monitor emails for keywords using regular expressions, which results in too many false positives that have to be manually reviewed. It is a very restrictive approach that can lead to false negatives, missing a large number of non-compliant emails.
To demonstrate how companies could ensure electronic document compliance more efficiently and effectively, data scientist Michiel Shortt and the A42 Labs team used a novel approach to analyze a million emails and attachments seized by prosecutors in the Enron scandal. Drawing upon A42 Labs’ expertise in integrating Greenplum Database and Nuix software, Shortt and the team developed an innovative approach to use these tools to perform large-scale machine learning across complex unstructured data.
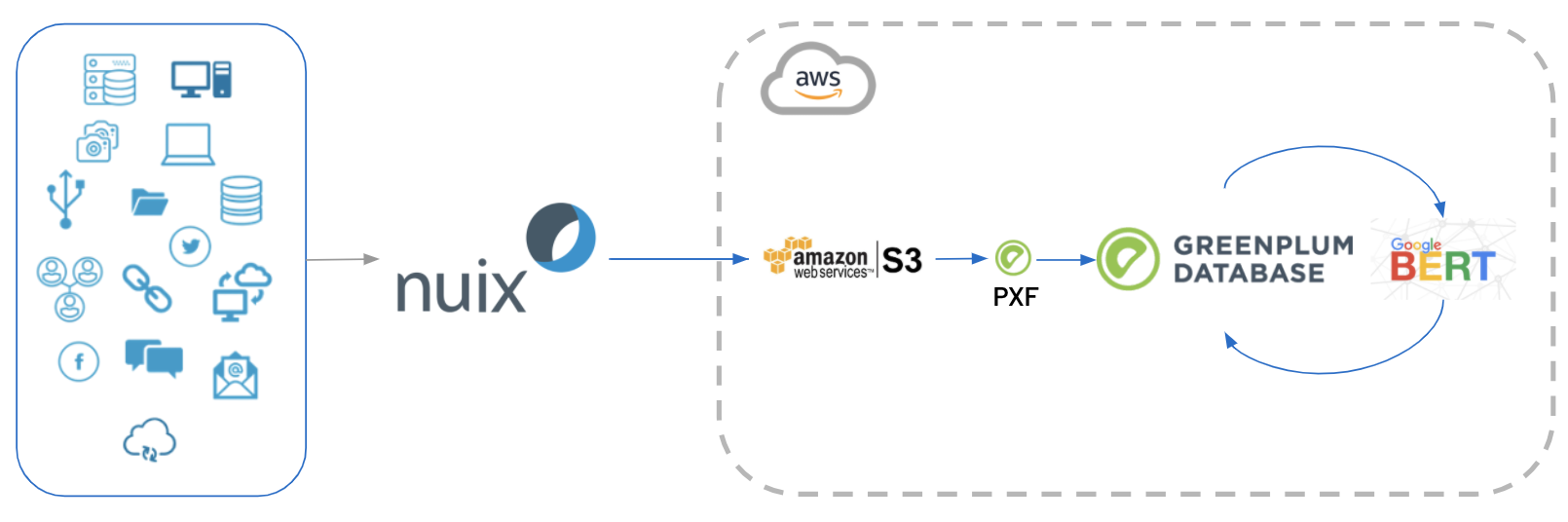
Considering the wide range of data types that comprise attachments—Office documents, PDF’s, images, and audio to name a few—analyzing these files is traditionally difficult and time-consuming. Nuix, a software platform for indexing, searching, analyzing and extracting knowledge from unstructured data, is capable of extracting metadata and content from a variety of file formats.
A42 Labs integrated Nuix and Greenplum to prepare unstructured data for modeling, then built a highly accurate email classification model that uses information from attachments to improve accuracy. Moreover, the team utilized Google BERT, a natural language processing technique that is highly effective at transforming formal and informal communications into numerical inputs for machine learning.
In this process, the email data is extracted to JSON using Nuix, then imported into a data store on AWS S3. In order to get these JSON files into Greenplum without a separate ETL process, the team leverages Greenplum’s PXF feature to rapidly import this data as external tables. Greenplum’s MPP architectures enable the team to perform on-the-fly queries as well as quickly transform the data into a usable format for BERT. While Google trained BERT using all of Wikipedia's text, it can be tuned further with the data in Greenplum. Once the BERT model is fully trained, the team reloads the trained model into Greenplum so that they can use Pl/Python to use it for inference to tell if an email a compliance violation.
The increased accuracy in results means less time identifying false positives, saving a significant amount of time and money. The process is automated and runs in the background to passively scan emails, instead of needing a person/team to manage it hands-on. It can be integrated with a company's current audit and compliance process and software.
For those who use Nuix, this is a great choice for presenting results. Email classifications can be deployed back into the Nuix engine from Greenplum for visualization and reporting through the Nuix dashboard.
When A42 Labs performed the same task for a client, the process reduced incorrect classification of documents (false positives) by more than 2,500 documents a day, resulting in an estimated $1 million in annual savings.
The ability to perform high-quality analysis on unstructured data of many different formats will improve electronic document compliance, helping organizations reduce the risk of employee malfeasance or lawsuits. Moreover, utilizing GPUs with Nuix and Greenplum makes this a highly scalable and cost-effective solution.
As demonstrated with both the Enron test case and A42 Labs’ client, this approach can greatly benefit enterprises looking to avoid legal peril, financial services companies aiming to curb insider trading, and lawyers performing document discovery. Beyond those use cases, the approach is generalizable, meaning that it can be applied to any problem that requires the modeling of large volumes of complex unstructured data.
If your organization is looking to apply machine learning for electronic document compliance or other high value data science use cases, contact us at info@a42labs.io to learn about how our team can help guide this transformation.
This blog has been edited by Paul Davis
